A couple of months ago, I wrote about how to use
Pentaho's REST services to
perform various user and role management tasks.
In that post, I tried to provide a few general guidelines to help developers interested in using the REST services, and, by way of example, I showed in detail how to develop a sample application that uses one particular service (namely, UserRoleDaoResource) from within the PHP language to perform basic user management tasks.
Recently, I noticed
this tweet from Rafael Valenzuela (
@sowe):
I suggested to use a Pentaho REST service call for that and I offered to share a little javascript wrapper I developed some time ago to help him get started.
Then, Jose Hidalgo (
@josehidrom) chimed in an expressed some interest so I decided to go ahead and lift this piece of software and develop it into a proper, stand-alone javascript module for everyone to reuse.
Introducing Phile
Phile stands for
Penta
ho F
ile access and is pronounced simply as "file". It is a stand-alone, cross-browser pure javascript module that allows you to build javascript applications that can work with the Pentaho respository.
The main use case for Phile is Pentaho BI Server plugin applications. That said, it should be possible to use Phile from within a server-side javascript environment like node js.
Phile ships as a single javascript resource. The unminified version,
Phile.js, includes
YUIDoc comments and weighs 32k. For production use, there's also a minified version available,
Phile-compiled.js, which weighs 5.7k.
You can simply include Phile with a
<script> tag, or you can load it with a module loader, like
require(). Phile supports the
AMD module convention as well as the
common js module convention.
Phile has its
YUIDoc api documentation included in the project.
Phile is released under the terms and conditions of the Apache 2.0 software license, but I'm happy to provide you with a different license if that does not, for some reason, suit your needs. The project is on
github and I'd appreciate your feedback and/or contributions there. Github is also the right place to
report any issues. I will happily accept your pull requests so please feel free to contribute!
Finally, the Phile project
includes a Pentaho user console plugin. This plugin provides a sample application that demonstrates pretty much all of the available methods provided by Phile. Installing and tracing this sample application is a great way to get started with Phile.
Getting started with Phile
In the remainder of this post, I will discuss various methods provided by Phile, and explain some details of the underlying REST services. For quick reference, here's a table of contents for the following section:
The recommended way to get started with Phile is to install the sample application unto your Pentaho 5.x server. This basic application provides a minimal but functional way to manipulate files and directories using Phile. Think of it as something like the
Browse files perspective that is built into the Pentaho user console, but implemented as a BI server plugin that builds on top of Phile.
To install the sample application, first download
phile.zip, and extract it into
pentaho-solutions/system. This should result in a new
pentaho-solutions/system/phile subdirectory, which contains all of the resources for the plugin. After extraction, you'll have to restart your pentaho BI server so the plugin gets picked up. (Should you for whatever reason want to update the plugin, you can simply overwrite it, and refresh the pentaho user console in your browser. The plugin contains no server side components, except for the registration of the menu item.)
Once restarted, you should now have a "Pentaho files" menu item in the "Tools" menu:
![]()
Note: Currently neither Phile nor the sample application are available through the Pentaho marketplace. That's because the sample application is only a demonstration of Phile, and phile itself is just a library. In my opinion it does not have a place in the marketplace - developers should simply download the Phile script files and include them in their own projects.
As you probably guessed, the sample application is started by activating the "Tools"> "Pentaho Files" menu. This will open a new "Pentaho Files" tab in the user console:
![]()
The user interface of the sample application features the following elements:
- At the very top: Toolbar with push buttons for basic functionality.
- The label on the buttons pretty much describes their function:
- New File
- Create a new file in the currently selected directory
- New Directory
- Create a new directory in the currently selected directory
- Rename
- Rename the currently selected file or directory
- Delete
- Move the currently selected file or directory to the trash, or permanently remove the currently selected item from the trash.
- Restore
- Restore the current item from the trash
- API Docs
- Opens the Phile API documentation in a new tab inside the Pentaho user console.
- Left top: Treeview.
- The main purpose of this treeview is to offer the user a way to navigate through the repository. The user can open and close folders by clicking the triangular toggle button right in front of a folder. Clicking the label of a file or folder will change the currently selected item to operate on. In response to a change of the currently selected item, the appropriate buttons in the toolbar are enabled or disabled as appropriate for the selected item. Initially, when the application is started, the tree will load the directory tree from the root of the repository down to the current user's home directory, and automatically select the current user's home directory. (In the screenshot, note the light blue highlighting of the
/home/admin folder, which is the home directory of the admin user.) - Left bottom: trash
- This is a view on the contents of the current user's trash bin. Unlike the treeview, this is a flat list of discarded items. Items in the trash can be selected just like items in the treeview. After selecting an item from the trash the appropriate toolbar buttons will be enabled and disabled to manipulate that item.
- Right top: properties
- Items stored in the repository carry internal metadata, as well as localization information. The properties pane shows the properties of the currently selected item in JSON format. JSON was chosen rather than some fancy, user-friendly form in order to let developers quickly see exactly what kinds of objects they will be dealing with when programming against the pentaho repository from within a javascript application.
- Right bottom: contents and download link
- If the currently selected item is a file, its contents will be shown in this pane. No formatting or pretty printing is applied to allow raw inspection of the file resource. In the title of the pane, a download link will become available to allow download of the currently selected resource for inspection on a local file system.
To get an idea of what the Phile API provides, click the "API Docs" button in the toolbar to open the API documentation. A new tab will open in the Pentaho user console showing the YUIDoc documentation. Inside the doc page, click the "Phile" class in the APIs tab (the only available class) and open the "Index" tab in the class overview:
![]()
Click on any link in the index to read the API documentation for that item. Most method names should give you a pretty good clue as to the function of the method. For example,
createDirectory() will create a directory,
discard() will remove a file or directory, and so on and so forth. We'll discuss particular methods in detail later in this post.
Now we'll take a closer look to what actually makes the sample application work. For now, you need only be concerned with the
index.html resource, which forms the entry point of the sample application.
The first thing of note is
the <script> tag that includes the Phile module into the page:
<script src="../js/Phile.js" type="text/javascript"></script>
Remember, you can either use the unminified source
Phile.js, which is useful for debugging and educational uses, or the minified
Phile-compiled.js for production use. The functionality of both scripts is identical, but the minified version will probably load a bit faster. The sample application uses the unminified script to make it easier to step through the code in case you're interested in its implementation, or in case you want to debug an issue.
The location of the script is up to you - you should choose a location that makes sense for your application and architecture. The sample application simply chose to put these scripts in a
js directory next to the location of
index.html, but if you want to use Phile in more than one application, it might make more sense to deploy it in a more central spot next to say the common ui scripts of Pentaho itself.
As noted before you can also dynamically load Phile with a javascript module loader like
require(), which is pretty much the standard way that Pentaho's own applications use to load javascript resources.
The next item of note in index.html is the
call to the
Phile()constructor:
var phile = new Phile();
This instantiates a new Phile object using the
default options, and assigns it to the
phile (note the lower case) variable. The remainder of the sample application will use the
Phile instance stored in the
phile variable for manipulating Pentaho repository files.
(Normally the default options should be fine. For advanced uses, you might want to pass a configuration object to the
Phile() constructor. Refer to the API documentation if you want to tweak these options.)
Virtually all methods of
Phile result in a HTTP request to an underlying REST service provided by the pentaho platform. Phile always uses asynchronous communication for its HTTP requests. This means the caller has to provide callback methods to handle the response of the REST service. Any Phile method that calls upon the backing REST service follows a uniform pattern that can best be explained by illustrating the generic
request() method:
phile.request({
success: function(
request, //the configuration object that was passed to the request method and represents the actual request
xhr, //The XMLHttpRequest object that was used to send the request to the server. Useful for low-level processing of the response
response //An object that represents the response - often a javascript representation of the response document
){
//handle the repsonse
},
failure: function(request, xhr, exception){
//handle the exception
//Arguments are the same as passed to the success callback,
//but the exception argument represents the error that occurred rather than the response document
},
scope: ..., //optional: an object that will be used as the "this" object for the success and failure callbacks
headers: {
//any HTTP request headers.
Accept: "application/json"
},
params: {
//any name/value pairs for the URL query string.
},
...any method specific properties...
});
In most cases, developers need not call the
request() method themselves directly. Most Phile methods provide far more specific functionality the generic request, and are implemented as a wrapper around to the generic
request() method. These more specific methods fill in as many of the specific details about the request (such as headers and query parameters) as possible for that specific functionality, and should thus be far easier and more reliable to invoke than the generic
request().
However, in virtually all cases the caller needs to provide the
success() and a
failure() callback methods to adequately handle server action. For each of the specific methods provided by Phile, the YUIDoc API documentation lists any specific options that apply to the configuration object passed to that particular method. You will notice that some of those more specific properties occur more often than others across different Phile methods. But the callback methods are truly generic and recur for every distinct Phile method that calls upon an underlying REST service.
The
request() method demonstrates the generic pattern for calling Phile methods, but the actual call will look different for various concrete requests. We'll take a look at a few of them as they are demonstrated by the sample application.
The sample application first
obtains the user's home directory by calling the
getUserHomeDir() method of the
Phile object. The
getUserHomeDir() method is implemented by making a HTTP GET request to services in the
/api/session API.
The sample application uses the home directory to determine how to fill the repository treeview:
//get the user home directory
phile.getUserHomeDir({
success: function(options, xhr, data){
var dir = data.substr(0, data.indexOf("/workspace"));
createFileTree(dir);
},
failure: failure
});
The
data argument returned to the
success callback is simply a string that represents the path of the user's home directory.
For some reason, paths returned by these calls always end in
/workspace, so for example, for the admin user we get back
/home/admin/workspace. But it seems the actual user home directory should really be
/home/admin, so we strip off the string
"/workspace". Then, we pass the remaining path to the
createFileTree() method of the sample application to fill the treeview.
As we shall see, when getting the repository structure for the treeview, the user home directory is used to decide how far down we should fetch the repository structure, and which directory to select initially.
In the example shown above, the argument object passed in the call the
getUserHomeDir() method of the
Phile object did not include a
user option. In this case, the home directory of the current user is retrieved with a GET request to
/api/session/userWorkspaceDir. But
getUserHomeDir() can also be used to retrieve the home directory of a specific user by passing the username of a specific user in the
name option to the argument object passed to
getUserHomeDir(). If the
user option is present, a GET request is done instead to
/api/session/workspaceDirForUser, which returns the home directory for that particular user.
The
createFileTree() function of the sample application obtains the repository structure to populate the treeview by doing a call to the
method of the
Phile object. The
getTree() in
Phile is implemented by doing a GET HTTP request to the
/api/repo/files/.../tree service.
function createFileTree(dir) {
var dom = document.getElementById("tree-nodes");
dom.innerHTML = "";
var pathComponents = dir.split(Phile.separator);
phile.getTree({
path: dir[0],
depth: dir.length,
success: function(options, xhr, data) {
createTreeBranch(data, pathComponents);
},
failure: failure
});
}
In the argument passed to
getTree(), we see two options that we haven't seen before:
path specifies the path from where to search the repository.depth is an integer that specifies how many levels (directories) the repository should be traversed downward from the path specified by the path option.
Many more methods of the
Phile object support a
path option to identify the file object that is being operated on. For flexibility, in each case where a
path option is supported, it may be specified in either of the following ways:
- As a string, separating path components with a forward slash. In code, you can use the static
Phile.separator property to refer to the separator. - As an array of path component strings. (Actually - any object that has a
join method is accepted and assumed to behave just like the join method of the javascript Array object)
Remember that the sample application initially populates the treeview by passing the user's home directory to
createFileTree(). In order to pass the correct values to
path and
depth, the user home directory string is split into individual path components using the static
Phile.separator property (which is equal to
"/", the path separator). Whatever is the first component of that path must be the root of the repository, and so we use
pathComponents[0] for
path (i.e., get us the tree, starting at the root of the repository). The
depth is specified as the total number of path components toward the user's home directory, ensuring that the tree we retrieve is at least so deep that it will contain the user's home directory.
The data that is returned to the
success callback is an object that represents the repository tree structure. This object has just two properties,
file and (optionally)
children:
file- An object that represents the file object at this level. This object conveys only information (metadata) of the current file object.
children- An array that represents the children of the current file. The elements in the array are again objects with a
file and (optionally) a children property, recursively repeating the initial structure.
Object like the one held by the
file property described above are generally used to represent files by the Pentaho REST services, and other
Phile API calls that expect file objects typically receive them in this format. They are basically the common currency exchanged in the Pentaho repository APIs.
Official documentation for file objects can be found here:
repositoryFileTreeDto.
From the javascript side of things, the
file object looks like this:
aclNode- String
"true" or "false" to flag if this is an ACL node or not. createdDate- A string that can be parsed as an integer to get the timestamp indicating the date/time this node was created.
fileSize- A string that can be parsed as an integer to get the size (in bytes) of this node in case this node represents a file. If a filesize is not applicable for this node, it is
"-1". folder- String
"true" or "false" to flag if this is node represents a folder or not. hidden- String
"true" or "false" to flag if this is node is hidden for the end user or not. id- A GUID identifiying this node.
locale- The current locale used for localized properties like
title. localeMapEntries- This is an array of localized properties for this file. The array items have these properties:
locale- The name of the locale for this map of localized properties. There is also a special
"default" locale indicating the current locale. properties- This is a bag of name/value pairs, representing localized properties.
key- The key for this property.
value- The value for this property.
locked- String
"true" or "false" to flag if this is node is locked or not. name- The name of this node.
ownerType- A string that can be parsed as an integer indicating the owner type.
path- A string containing the forward slash separated path components.
title- The title for presenting this node to the user.
versioned- String
"true" or "false" to flag if this is node is versioned or not. versionId- If the file is versioned, the
versionId property is present and its value is a String that represents the version number.
Note that the list of properties above is just a sample: Depending on context, some properties might not be present, or extra properties may be present that are not listed here. But in general, key properties like
id,
path,
folder,
dateCreated,
name and
title will in practice always be present.
There are a few things that should be noted about the file object. What may strike you by surprise is that in the raw JSON response, all scalar properties are represented as strings. For example, properties a like
folder and
hidden and so on look like they should be booleans, but their value is either
"true" or
"false", and not, as one might expect,
true and
false. Likewise, integer fields like
fileSize, and timestamp fields like
dateCreated are also represented as strings - not as integers.
There is not really any good reason why the Pentaho REST service uses string representations in its response, since there are proper ways to express these different types directly in JSON. However, things are the way they are and there's not much Phile can (or should) do to change it. For convenience it might be a good idea to add a conversion function to Phile which turns these strings into values of a more appropriate datatype. Remember, contributions and pull requests are welcome!
For convenience, most of the
Phile methods that require a
path option can also pass a
file option instead. If a
file option is passed, it is expected to adhere to the structure of the
file object described above. In those cases,
Phile will use the
path property of the passed file object as the
path option. This allows application developers to use the file objects as they are received from the Pentaho server directly as input for new calls to the
Phile API. (That said, the sample application currently does not use or demonstrate this feature and passes an explicit
path instead.
We just discussed how the
getTree() method could retrieve the structure of the repository from one particular path up to (or rather, down to) a specific level or depth. There is a very similar method for obtaining the contents of only a single directory:
getChildren(). This is implemented by calling the
/api/repo/files/.../children service. In the sample application,
this is used to populate the (hitherto unpopulated and collapsed) folder nodes in the treeview:
function getChildrenForPath(path){
phile.getChildren({
path: path,
success: function(options, xhr, data) {
if (!data) {
return;
}
var files = data.repositoryFileDto, i, n = files.length, file;
sortFiles(files);
for (i = 0; i < n; i++){
file = files[i];r
createTreeNode(file);
}
},
failure: failure
});
}
Just like in the call to
getTree() a
path option must be specified. The
getChildren() call does not support a
depth option, which makes sense since it only returns the contents of the specified directory. (In other words, unlike
getTree(),
getChildren is not recursive, so it makes no sense to specify or require a "depth".)
Because
getChildren() only returns the contents of the specified directory, the structure of the response data passed to the
success() callback differs slightly from what is returned by
getTree(): in the case of
getChildren(), the response data is a javascript object that has a single
repositoryFileDto property, which is an array of
file objects:
{
"repositoryFileDto": [
...many file objects...
]
}For each user, the repository has a special trash folder that is used as temporary storage for discarded files (and directories). The trash folder cannot (should not) be approached directly with a call to
getChildren() or
getTree(). Instead, there is a special method available called
getTrash() to list the contents of the trash folder. This method is implemented by doing a GET request to the
/api/repo/files/deleted service.
The sample application reads the contents of the trash folder to populate the list in the left bottom of the screen with the
loadTrash() function:
function loadTrash() {
phile.getTrash({
success: function(options, xhr, data){
var thrashList = document.getElementById("trash-nodes");
createFileList(data, thrashList);
},
failure: failure
});
}
As you can see,
loadTrash() simply calls the
getTrash() method on the
Phile instance, and uses the
data passed back to the
success() callback to build the list.
The data that
getTrash() passes back to the callback has essentially the same structure as what is passed back by the
getChildren() method: an object with a single
repositoryFileDto property, which holds an array of
file objects. However, since the
file objects are in the trash, they have a couple of properties that are specific to discarded items:
deletedDate- A string that can be parsed as an integer to get the timestamp indicating the date/time this node was deleted.
originalParentFolderPath- A string that holds the original path of this file object before it was discarded to the trash folder. This is essential information in case you want to restore an item from the trash, since its actual own
path property will be something like /home/admin/.trash/pho:4cce1a1b-95e2-4c2e-83a2-b19f6d446a0d/filename and refers to its location in the trash folder, which most likely means nothing to an end user.
The sample application handles a click event on the "New Directory" toolbar button by calling the
newDirectory() function. This function calls the
createDirectory() method of the
Phile object to create a new directory inside the currently selected directory:
function newDirectory(){
var path = getFileNodePath(selected);
var name = prompt("Please enter a name for your new directory.", "new directory");
if (name === null) {
alert("You did not enter a name. Action will be canceled.");
return;
}
var newPath = path + Phile.separator + name;
phile.createDirectory({
path: newPath,
success: function(xhr, options, data) {
selected.lastChild.innerHTML = "";
selected.setAttribute("data-state", "expanded");
getChildrenForPath(path);
},
failure: failure
});
}
As you can see, the user is presented with a prompt to get a name for a new directory, and this is simply appended to the path of the currently selected directory. This new path is then passed in the
path property of the argument to the
createDirectory method of the
Phile object. (Please note that a serious application would provide some checks to validate the user input, but in order to demonstrate only the principles of using Phile, the sanmple application takes a few shortcuts here and there.)
The
createDirectory() method is implemented by doing a
PUT request to the
/api/repo/dirs service. One might expect to be returned a
file object that represents the newly created directory, but alas this is not the case: the request does not return any data. The sample application refreshes all of the children of the parent directory instead. (Please note that this is just a quick way to ensure the treeview reflects the new state of the directory accurately. A serious application should probably change the gui to add only the new directory, and otherwise retain the state of the tree. Again this is a shortcut just to keep the sample application nice and simple.)
When working with methods like
getTree(),
getChildren() and
getTrash(), it may be needed to sort an array of file objects. For example, in the sample application, the treeview first presents all folders, and then the files, and within these types of file objects, the items are sorted alphabetically. The trash pane takes a different approach, and sorts all files based on their original path.
In the sample application this is achieved simply by calling the native
sort() function on the array in which the file objects are received. But to achieve a particular type of sort, a comparator function is passed into the sort function.
Phile offers a number of static general purpose file comparators:
compareFilesByPathCS()- Compares files by path in a case-sensitive (CS) manner.
compareFilesByOriginalPathAndName()- Compares files by orginal path, and then by name (in a case-sensitive manner).
compareFilesByTitleCS- Sorts folders before files, and then by title in a case-sensitive manner (CS).
compareFilesByTitleCI- Sorts folders before files, and then by title in a case-insensitive manner (CS).
Each of these methods can be of use in certain contexts. For example, the comparison implemented by
compareFilesByPathCS() will by many people be regarded as the "natural" order of file objects, and this might be a useful sort order for things like autocomplete listboxes and such. The
compareFilesByTitleCS() and
compareFilesByTitleCI() methods on the other hand implement an order that is most suitable when presenting the files in a single directory in a GUI. And
compareFilesByOriginalPathAndName() may prove to be useful when sorting items from the trash, since it takes the original name and location into account rather than the actual, current name and location.
The sample application uses the
sortFiles() function to sort files in the treeview:
function sortFiles(files){
files.sort(Phile.compareFilesByTitleCI);
}
As you can see, it's simply a matter of calling
sort() on the array of files and passing the appropriate comparator. Since the comparators are static properties of the
Phile constructor itself, it's qualified by prepending
Phile. to its name.
Phile offers a useful utility method to generate new comparators called
createFileComparator(). The
createFileComparator() is static an attached as a property directly to the
Phile constructor itself, so in order to call it, it must be qualified, like so:
Phile.createFileComparator().
The
createFileComparator() takes a single argument, which represents a sort specification. It returns the comparator function that can be passed to the native
sort() method of the javascript
Array object.
The sort specification passed to
createFileComparator() should be an object. Each property of this object indicates the name of a property in the
file objects that are to be compared. The value of the property in the sort specification should be an object that contains extra information on how to treat the respective file in the comparison.
In the simplest case, the properties of the sort specification are all assigned
null. In this case the fields will be compared as-is, which in practice means the field values of the file objects are compared in case-sensitive alphanumerical order. This is how the built-in comparator
compareFilesByPathCS() is created:
Phile.compareFilesByPathCS = Phile.createFileComparator({
path: null
});
This sort specification simply states that file objects must be compared by comparing the value of their respective
path property. The built-in comparator
compareFilesByOriginalPathAndName() is constructed similarly, but specifies that both
originalPath and
name fields are to be compared (in order):
Phile.compareFilesByOriginalPathAndName = Phile.createFileComparator({
originalParentFolderPath: null,
name: null
});
You can exert more control on how fields are compared by assigning an actual object to the respective property in the sort specification instead of
null. When an object is assigned, you can set a
direction property with a value of
-1 to indicate reverse sort order.
This is put to good use by the built-in comparators
compareFilesByTitleCS and
compareFilesByTitleCI to ensure that folders are sorted before regular files:
Phile.compareFilesByTitleCS = Phile.createFileComparator({
folder: {direction: -1},
title: null
});
By first sorting on the
folder property and after that on the
title property, we achieve the desired presentation that most user will be accustomed to. However, the
folder property will have a string value of either
"true" or
"false". Since we want all folders to be sorted before all files, we need to reverse the order (since
"true" is larger than
"false"). The sort specification
{direction: -1} does exactly that.
Sometimes, it can be useful to exert control on the actual values that will be compared. To this end, you can specify a custom converter function in the field sort specification via the
convert property. The specified function will then be applied to the raw field value, and the return value of the converter function will be used in the comparison rather than the raw value.
The built-in
compareFilesByTitleCI comparator uses the
convert property in the sort specification to implement a case-insensitive comparison:
Phile.compareFilesByTitleCI = Phile.createFileComparator({
folder: {direction: -1},
title: {convert: function(value){return value.toUpperCase();}}
});
In this sort specification, a
convert function is specified for the
title field, which accepts the original, raw title, and returns its upper case value by applying the built-in
toUpperCase() method of the javascript
String object. Since the upper case values rather than the raw values will be compared, this ensures the comparison is now case-insensitive.
Besides implementing case-insensitive comparison, specifying a
convert function can be of use in other cases as well. For instance, if you want to sort on file creation date, you could specify a
convert function that parses the
createdDate property of the
file object and returns its integer value to as to achieve a chronological order.
Now that we know how to use
Phile to work with directories, let's take a look at working with files.
Whenever the user of the sample application clicks the label of an item in either the treeview (left top) or the trash file list (left bottom), the current selection changes, and the properties pane (right top) will refresh and show the properties of the currently selected file. This provides a view of the corresponding
file object as it is known in the repository.
The selection of an item is handled by the
labelClick() function of the sample application. This method handles quite a bit of logic that is specific to the sample application, and we won't discuss it in full. Instead, we focus on the bit that retrieves the properties of the selected file, which is done with a call to the
getProperties() method of the
Phile object:
phile.getProperties({
path: getFileNodePath(node),
success: function(options, xhr, data){
var propertiesText = document.getElementById("properties-text");
propertiesText.innerHTML = "";
displayProperties(data, propertiesText);
},
failure: failure
});
As we have seen in many other
Phile calls, the
path property of the object passed to the method provides the actual input. In this particular sample code, the value for
path is extracted from the DOM element that represents the selected item in gui (this is held by the
node variable), and the
getFileNodePath() function simply extracts the path. (The details of that are not really relevant to using
Phile and analysis of that code is left as an exercise to the reader.)
The
data argument passed to the
success() callback passed to the
getProperties() method returns the properties of the file identified by the
path property as a
file object. The sample application simply clears the properties pane and then fills it with a JSON string representation of the object (by calling the
displayProperties() function).
The actual make up of the returned
file object will depend on whether the
path identifies a regular file, a folder, or an discarded item in the trash folder. But the
getProperties() method can be used in any of these cases to retrieve the properties of these items from the repository.
In the sample application, changing the selection also affects the contents pane (right bottom). Changing the selection always clears whatever is in there, but if the newly selected item is a file (and not a directory or an item in the trash folder), its contents will also be displayed there.
Loading the content pane is handled by the
labelClick() function, which is also responsible for loading the properties pane. The contents of the file are obtained with a call to the
getContents() method of the
Phile object:
phile.getContents({
path: getFileNodePath(node),
headers: {
Accept: "text/plain"
},
success: function(options, xhr, data) {
displayContents(options.path, xhr.responseText);
},
failure: failure
});
As usual, the
path option is used to tell the method of which file the contents should be retrieved.
There are two features in this call to
getContents() that we have not witnessed in any other
Phile method call, and which are unique to this method:
- A HTTP
Accept header is specified to ensure the contents are retrieved as plain text (as indicated by the text/plain mime type value). - Rather than using the
data argument passed to the success() callback, the responseText property of the actual XMLHttpRequest that was used to do the request to the REST service. That's because in this case, we only want to display the literal contents of the file. The exact type of the data passed to the success() callback may vary depending on the Content-Type response header, which is not what we want right now since we're interested in displaying only the raw file contents. This is exactly why the success() callback (as well as the failure() for that matter) is passed the actual XMLHttpRequest object - to access any lower level properties that might require custom handling.
When a file is selected, the title of the content pane (right bottom) presents a link to the end user that allows them to download the contents of the file. The url that may be used to download a particular file can be generated using the
getUrlForDownload() method of the
Phile object.
In the sample application, the download link is created in the
displayContents() function, which is called after selecting a file item:
function displayContents(path, contents){
var a = document.getElementById("contents-download");
a.textContent = path;
a.href = phile.getUrlForDownload(path);
var contentsText = document.getElementById("contents-text");
contentsText.innerHTML = escapeHtml(contents);
}
The
getUrlForDownload() method takes a single
path argument, and returns a string that represents a url that can be used to download the file. As usual, the
path argument may be either a string, or an array of path components.
Note that generating the download link only involves string manipulation, and does not entail calling a backend REST service. Rather, when the generated url is used as the
href attribute for a html-
<A> element, clicking that link will access the REST service and initiate a download from the server. Therefore, this method does not require or accept callbacks, since generating the download link is not an asynchronous process.
In the previous section, we discussed how you can use the
createDirectory() method of the
Phile object to create a new directory. The
Phile object also features a
saveFile() to create and write regular files.
The sample application offers a "New File" button that allows the user to create a new file in the current directory. Clicking the button will invoke the
newFile() function, which invokes the
saveFile() method on the
Phile object. The relevant snippet is shown below:
phile.saveFile({
path: newPath,
data: contents,
success: function(xhr, options, data) {
selected.lastChild.innerHTML = "";
selected.setAttribute("data-state", "expanded");
getChildrenForPath(path);
},
failure: failure
});
The call to
saveFile() is quite similar to the one made to
createDirectory(): the file that is to be created is conveyed by means of the
path property in the argument to
saveFile(), and the contents of the file are passed in via the
data property. Just like in the case of
createDirectory(), the callback does not receive any data; it would have been useful to receive an object that represents the newly created file but alas.
The
saveFile() method can also be used to overwrite the contents of an existing file. You can test this in the sample application by entering the name of an existing file. Please note that neither the
saveFile() method itself, nor the sample application warn against overwriting an existing file, but a serious application should probably check and prompt the user in such a case.
The
saveFile() method is implemented by making a HTTP
PUT request to the
/api/repo/files service.
Phile also offers methods for discarding, restoring and renaming files.
Discarding a file means it will be removed from the user's point of view. This can either mean it is moved to the trash folder, or permanently deleted from the repository. Phile supports both operations using a single
discard() method.
In the sample application, both modes of the
discard() method are demonstrated in the
deleteSelected() function:
function deleteSelected(){
if (!selected) {
return;
}
var request = {
success: function(options, xhr, data) {
selected.parentNode.removeChild(selected);
loadTrash();
},
failure: failure
};
var message, permanent;
var properties = getFileNodeProperties(selected);
var path = properties.path;
if (selected.parentNode.id === "trash-nodes") {
message = "Are you sure you want to permanently remove ";
request.permanent = true;
request.id = properties.id;
}
else {
request.path = path;
message = "Are you sure you want to discard ";
}
if (!confirm(message + path + "?")) {
return;
}
phile.discard(request);
}
The function builds a single
request object which is passed to the
discard() method of the
Phile object in the last line of the function. Depending on whether the currently selected item is in the trash or a regular file or directory, different properties are set on the
request object:
- If the item is in the trash, a
permanent property is set to true to indicate that the item should be permanently removed from the repository. Note that the permanent property can always be specified, even if the item is not in the trash. It's just that the sample application was designed to only permantly remove items from the trash. In addition, the id property is set on the request object to which the value of the id property of the file object is assigned. - If the item is not in the trash (and is thus either a directory or a regular file), only a
path is set on the request object.
The
success() callback is also set on the
request, which removes the item that corresponds to the removed file from the gui and refreshes the view of the trash. The callback does not receive any data. This makes sense in case the object was permanently removed, but in case of moving the item to the crash it would have been nice to receive the
file object that represents the moved file.
The
discard() method has a slightly more complex implementation than any other method in the
Phile object.
Ultimately, calling the
discard() method results in a HTTP PUT request to either the
delete or the
deletepermanent service of the
/api/repo/files API. The choice for
delete or
deletepermanent is controlled by the value of the
permanent property on the argument passed to
discard():
- If
permanent is true, deletepermanent will be used and the item will be permanently removed from the repository. - If
permanent is absent or at least, not true, delete will be used and the item will be moved to the current user's trash folder.
However, unlike most (all?) other services that manipulate files and directories,
delete and
deletepermanent require that the file or directory to operate on is specified by it's
id. As you might recall from our description of the
file object, this is a GUID that uniquely identifies any item within the repository. So, to make the
discard() function behave more like the other methods of the
Phile object, measures have been taken to allow the caller to specify the file either as a
path, or with a
id: if an
id is specified, that will always be used. But if no
id is specified,
Phile will see if a
path was specified, and use that to make a call to
getProperties() in order to retrieve the corresponding
file object to extract its id, and then make another call to
discard() using that id.
We mentioned earlier that as a convenience, you can specify a
file object via the
file property instead of a
path, in which case the
path property would be taken from that
file object. The
discard() method can also accept a
file object as a specification for the file to be discarded, but in that case
discard() will directly use the
id property of that
file object.
You can restory items from the trash with the
restore() method. The sample application demonstrates its usage in the
restoreSelected() function:
function restoreSelected(){
if (!selected) {
return;
}
var properties = getFileNodeProperties(selected);
phile.restore({
file: properties,
success: function(options, xhr, data){
var path = properties.originalParentFolderPath + Phile.separator + properties.name;
createFileTree(path);
loadTrash();
},
failure: failure
});
}
Currently you can specify the item to be restored from the trash using either an
id or a
file option. The sample application uses the latter. Currently, it is not possible to specify the file to be restored by its
path (but you're welcome to implement it and send me a pull request). However, I currently feel that is not really that big of a problem, and might actually be a little bit confusing since items in the trash have both a
path and an
originalParentFolderPath.
The actual implementation of the
restore() method relies on doing a HTTP PUT request to the
/api/repo/files/restore service.
The
rename() method can be used to rename files or directories. The sample application demonstrates its use in the
renameSelected function:
function renameSelected(){
if (!selected) {
return;
}
var newName = prompt("Please enter a new name for this file.", "new name");
if (newName === null) {
alert("You did not enter a name. Action will be canceled.");
return;
}
var path = getFileNodePath(selected);
phile.rename({
path: path,
newName: newName,
success: function(options, xhr, data){
debugger;
},
failure: failure
});
}
As usual, the file to operate on can be specified with a
path (or
file) property. The new name for the item should be a string and can be specified via the
newName property.
The actual implementation of the
rename() method relies on doing a HTTP PUT request to the
/api/repo/files/rename service. However, I'm experiencing a problem in that this always results in a HTTP 500 status (Internal server error). However, the actual rename action does succeed. I filed a bug to report this issue here:
BISERVER-12695.
Finally...
I hope this post was useful to you. Feel free to leave a comment on this blog. If you have a specific question about the project, then please report an issue on the github issue tracker. Remember, your feedback is very welcome, and I will gladly consider your requests to improve Phile or fix bugs. And I'd be even happier to receive your pull requests.





 There are a few differences with regard to the output of kettle's Row Normalizer step:
There are a few differences with regard to the output of kettle's Row Normalizer step: And here endeth the lesson.
And here endeth the lesson.
 Get data from XML
Get data from XML HTTP Client step
HTTP Client step Text file output step
Text file output step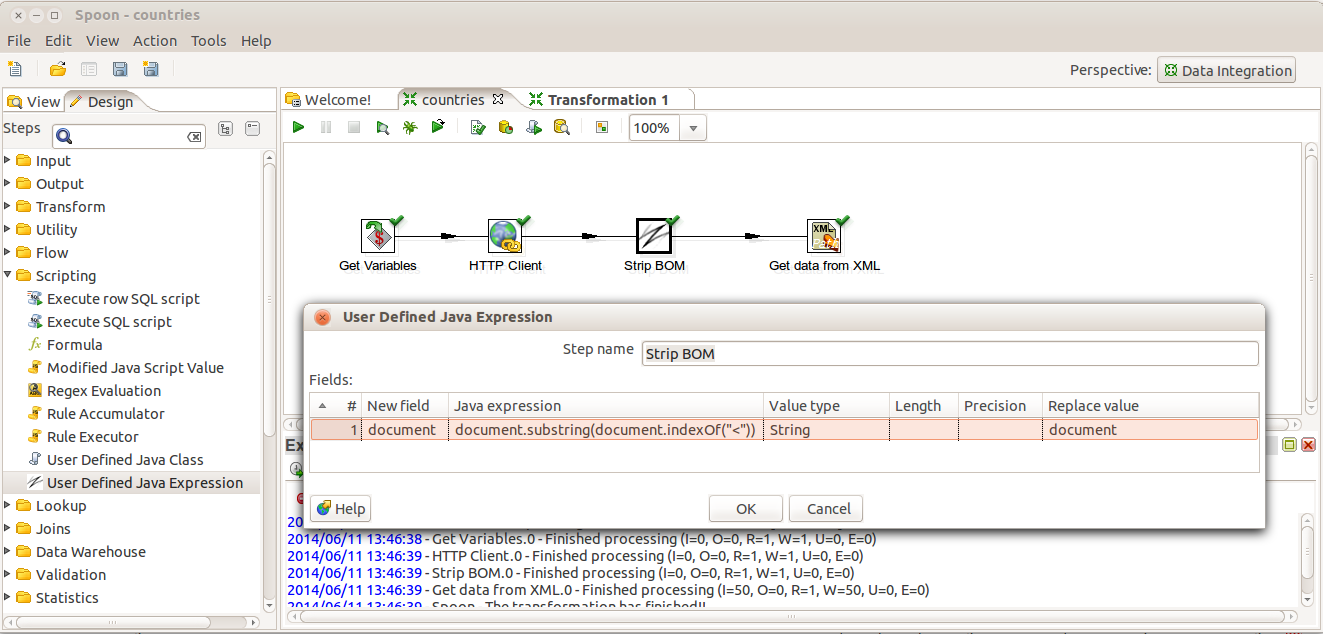 So, the "HTTP client" step retrieves the XML text in the
So, the "HTTP client" step retrieves the XML text in the  User-defined Java Expression
User-defined Java Expression